What Is the Role of Pub/Sub in Data Engineering?

- What Is the Role of Pub/Sub in Data Engineering?
- Introduction
- Understanding Pub/Sub in Google Cloud
- Why Pub/Sub Matters in Data Engineering
- Role of Pub/Sub in Streaming Data Pipelines
- Event-Driven Architecture and Pub/Sub
- Improving Data Quality and Pipeline Stability
- Security and Governance in Pub/Sub
- Cost and Performance Considerations
- Common Use Cases of Pub/Sub in Data Engineering
- FAQs
- Conclusion
Introduction
GCP Data Engineer professionals work at the center of modern analytics systems where data is generated continuously from applications, devices, and users. In today’s digital environments, data rarely arrives in neat batches; instead, it flows in real time from websites, mobile apps, IoT sensors, and enterprise systems. Handling this constant stream efficiently is a core challenge in data engineering. This is where GCP Data Engineer Course learners often first encounter Google Cloud Pub/Sub as a foundational service for building reliable, event-driven pipelines. Pub/Sub plays a crucial role in decoupling systems, enabling scalability, and ensuring data is delivered exactly when it is needed.
Understanding Pub/Sub in Google Cloud
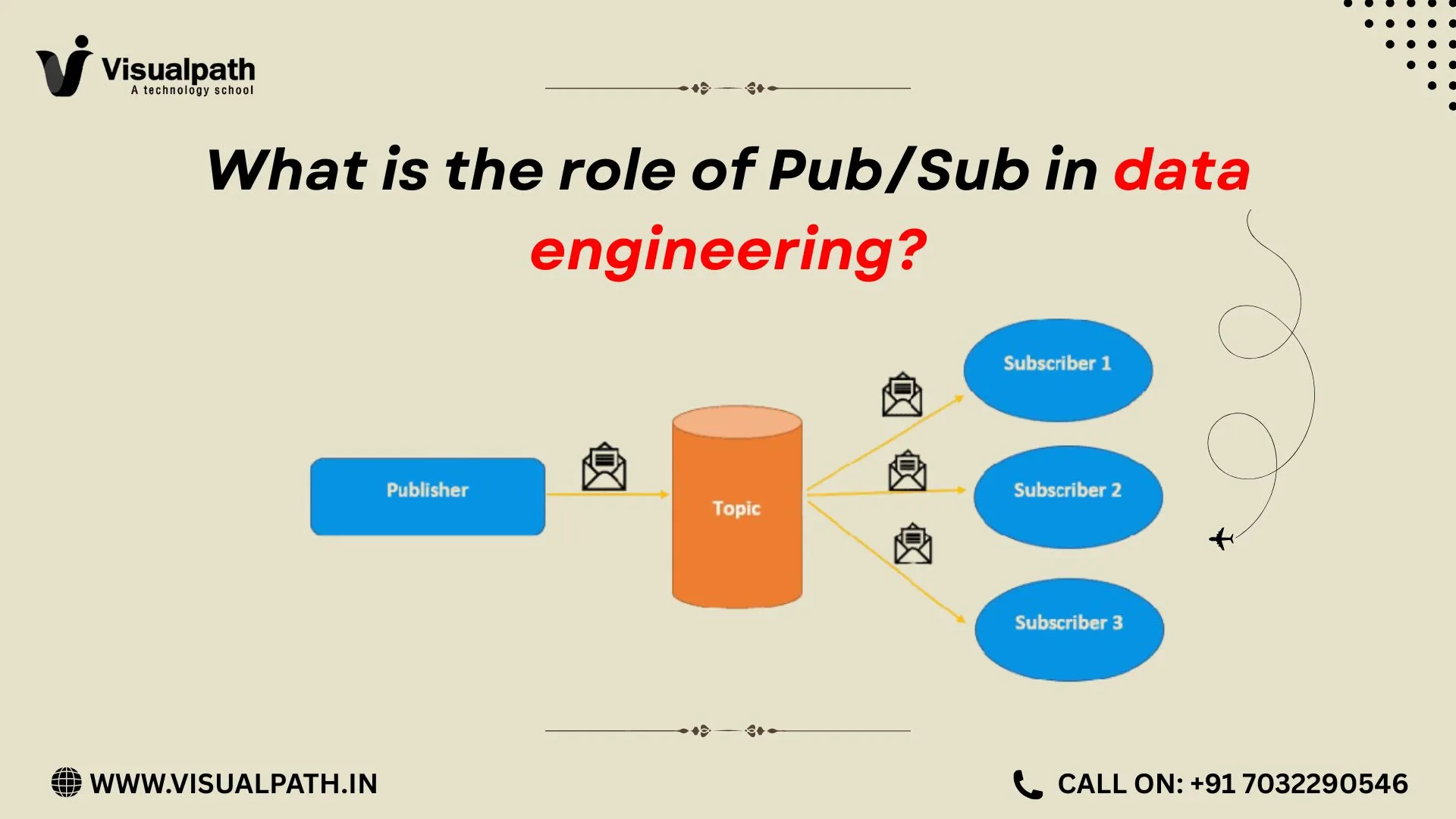
Pub/Sub is a fully managed, asynchronous messaging service designed for real-time data ingestion and event distribution. It follows a publish–subscribe model, where producers (publishers) send messages to a topic, and consumers (subscribers) receive those messages independently.
From a data engineering perspective, Pub/Sub acts as the front door for streaming data. It accepts millions of events per second without requiring engineers to manage infrastructure. Because it is serverless, teams can focus on data logic rather than scaling concerns, capacity planning, or message durability.
Why Pub/Sub Matters in Data Engineering
Modern data platforms rely on speed, reliability, and flexibility. Pub/Sub supports all three.
First, it enables real-time ingestion. Whether the source is application logs, clickstream events, transaction data, or sensor readings, Pub/Sub can ingest data the moment it is produced.
Second, it supports system decoupling. Data producers do not need to know who consumes the data. This allows engineers to add new analytics pipelines, monitoring tools, or machine learning consumers without touching the source systems.
Third, Pub/Sub provides global scalability. It automatically scales to handle sudden spikes in traffic, making it ideal for unpredictable workloads such as marketing campaigns or live events.
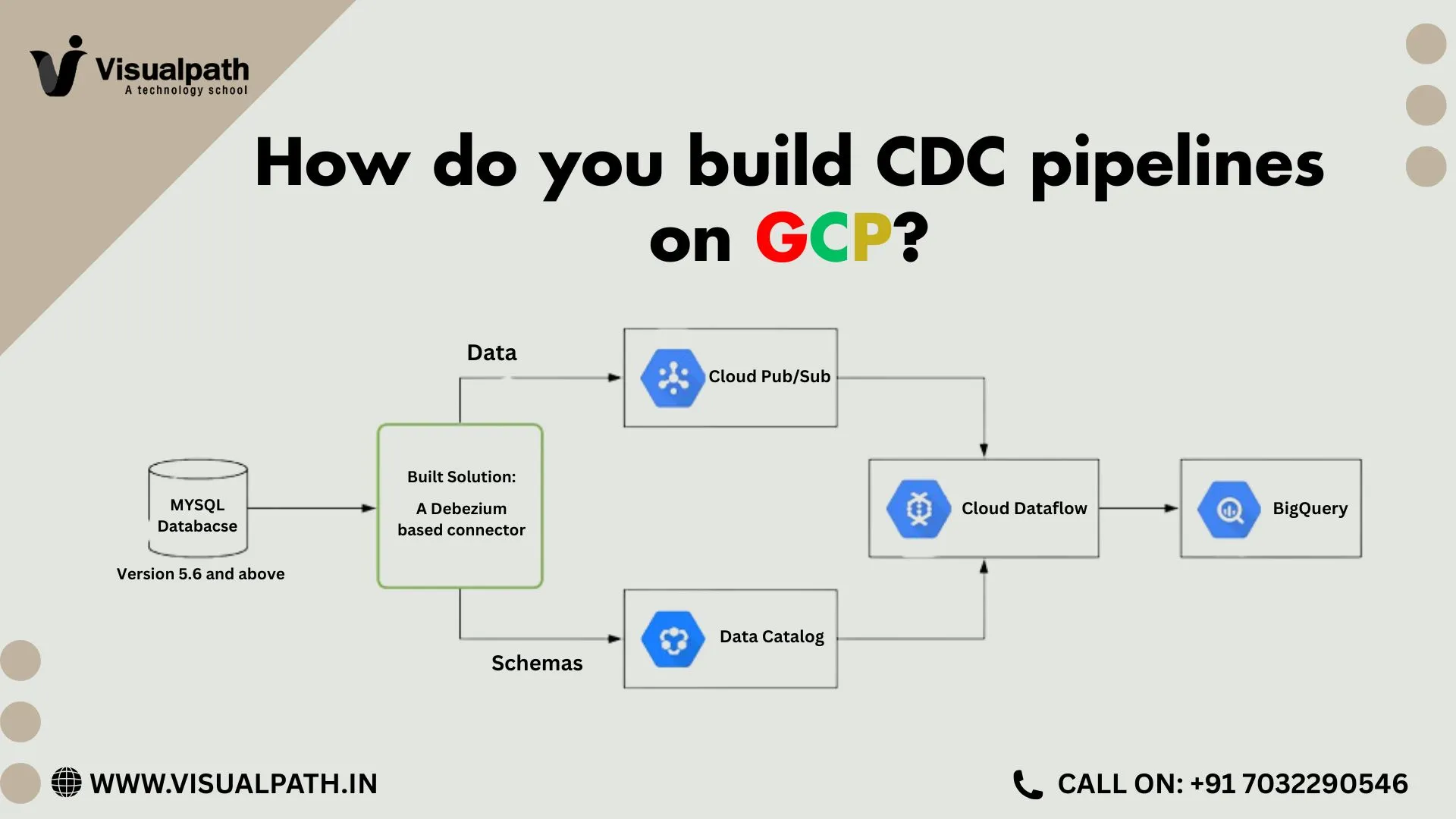
Role of Pub/Sub in Streaming Data Pipelines
Pub/Sub forms the backbone of streaming data pipelines on Google Cloud. In a common architecture, applications publish events to Pub/Sub topics. Processing engines such as Dataflow then consume those events, apply transformations, and load curated data into analytics systems like BigQuery.
Engineers frequently practice this design in GCP Data Engineer Online Training because it mirrors real production environments. Pub/Sub ensures message durability, so data remains available even when downstream systems experience temporary failures. This reliability supports critical use cases such as fraud detection, operational monitoring, and live dashboards.
Event-Driven Architecture and Pub/Sub
Event-driven architecture has become a standard pattern in cloud-native systems. Pub/Sub is a natural fit for this approach.
In event-driven systems, actions occur in response to events rather than fixed schedules. Pub/Sub allows data engineers to trigger workflows whenever new data arrives. For instance, when a transaction event is published, it can simultaneously trigger real-time dashboards, anomaly detection models, and alerting systems.
This pattern improves responsiveness and reduces latency across the data ecosystem. It also simplifies system design by removing tight dependencies between services.
Improving Data Quality and Pipeline Stability
Streaming pipelines often face challenges related to data quality and bursty traffic. Pub/Sub absorbs traffic spikes and delivers messages at a consistent rate to subscribers.
Engineers can route problematic messages to dead-letter topics when processing fails. This strategy prevents pipeline interruptions and allows teams to investigate issues without losing data. Pub/Sub therefore supports stable pipelines that continue running even under imperfect data conditions.
Security and Governance in Pub/Sub
From an enterprise standpoint, Pub/Sub supports fine-grained access control using IAM roles. Data engineers can restrict who can publish or subscribe to specific topics, helping enforce data governance policies.
The platform encrypts data automatically and supports compliance requirements for enterprise workloads. These features make Pub/Sub suitable for sensitive and regulated data environments.
Cost and Performance Considerations
Pub/Sub uses a pay-as-you-go pricing model based on data volume. This makes it cost-effective for both small projects and large-scale enterprise systems. Engineers can optimize costs by designing efficient message schemas and managing retention policies carefully.
Performance-wise, Pub/Sub delivers low-latency message delivery across regions. This makes it suitable for real-time analytics, operational dashboards, and time-sensitive decision-making systems often covered in GCP Data Engineer Training in Hyderabad.
Common Use Cases of Pub/Sub in Data Engineering
Data engineers use Pub/Sub in many real-world scenarios, including:
- Real-time analytics pipelines
- Log aggregation and monitoring
- IoT data ingestion
- Event-driven ETL processes
- Machine learning feature streaming
In all these cases, Pub/Sub acts as the backbone that connects data producers with processing and storage layers.
FAQs
Conclusion
Pub/Sub plays a central role in modern data engineering by enabling real-time data flow, scalable architectures, and event-driven systems. It simplifies the ingestion of continuous data streams while providing reliability, security, and flexibility. For data engineers building cloud-native platforms, Pub/Sub is not just a messaging service—it is a foundational component that connects data sources, processing engines, and analytics platforms into a cohesive, responsive ecosystem.
TRENDING COURSES: Oracle Integration Cloud, AWS Data Engineering, SAP Datasphere
Visualpath is the Leading and Best Software Online Training Institute in Hyderabad.
For More Information about Best GCP Data Engineering
Contact Call/WhatsApp: +91-7032290546
Visit: https://www.visualpath.in/gcp-data-engineer-online-training.html