
How Do You Build CDC Pipelines on GCP?

- How Do You Build CDC Pipelines on GCP?
- Introduction
- Why CDC Is Essential in Modern GCP Data Architectures
- Core Building Blocks of a CDC Pipeline on GCP
- Capturing Changes Using Datastream
- Streaming CDC Events with Pub/Sub
- Transforming and Enriching Data Using Dataflow
- Loading CDC Data into BigQuery Correctly
- Managing Schema Evolution in CDC Pipelines
- Monitoring, Reliability, and Cost Control
- Security and Compliance Considerations
- FAQs
- Conclusion
Introduction
GCP Data Engineer workflows increasingly depend on real-time data availability. Change Data Capture enables organizations to move only the data that changes, reducing latency, cost, and complexity while keeping analytics systems continuously updated. In modern cloud environments, batch-only processing is no longer enough. Teams need systems that respond instantly to business events, user behavior, and operational changes. This growing demand for always-fresh data is why CDC has become a critical skill for professionals enrolling in a GCP Data Engineer Course and working on enterprise-scale data platforms.
Change Data Capture focuses on identifying inserts, updates, and deletes directly from source databases and delivering them downstream with minimal delay. Instead of reloading entire tables, CDC pipelines track changes at the log level, ensuring accuracy while improving performance and efficiency.
Why CDC Is Essential in Modern GCP Data Architectures
Traditional ETL pipelines were designed for static reporting needs. They run on schedules, consume significant resources, and introduce latency. CDC pipelines, on the other hand, align perfectly with real-time analytics, operational dashboards, and event-driven systems.
Organizations use CDC on GCP to:
- Keep BigQuery analytics tables continuously updated
- Power real-time dashboards and alerts
- Synchronize transactional and analytical systems
- Enable downstream machine learning pipelines
In industries like finance, retail, logistics, and healthcare, even a few minutes of data delay can impact decision-making. CDC bridges this gap efficiently.
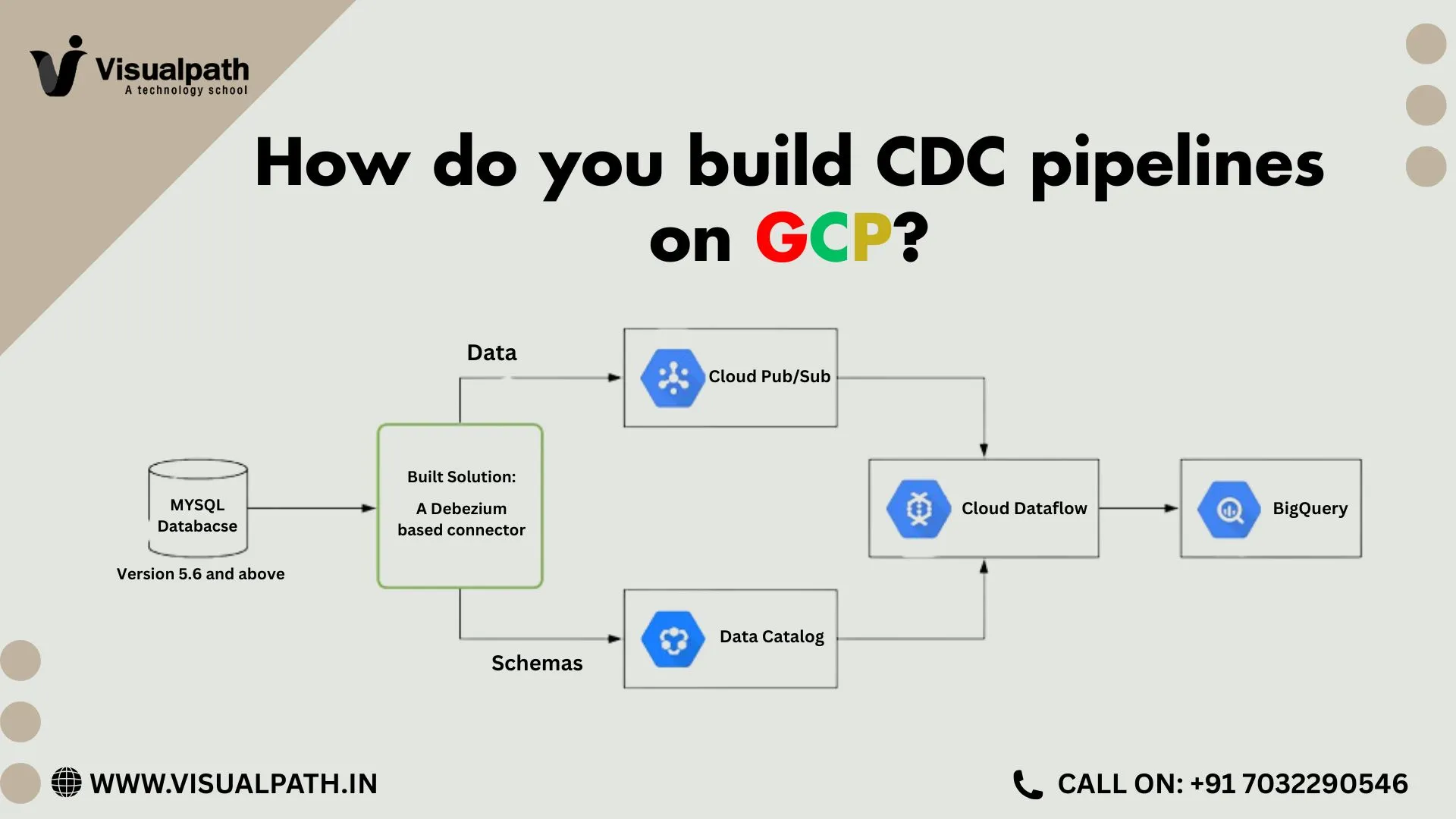
Core Building Blocks of a CDC Pipeline on GCP
A reliable CDC pipeline on Google Cloud is built using multiple integrated components, each serving a specific role:
Source Databases
Most CDC pipelines start with relational databases such as MySQL, PostgreSQL, Oracle, or SQL Server. CDC tools read transaction logs rather than querying tables, ensuring minimal impact on production systems.
Change Capture Layer
This layer is responsible for detecting data changes. On GCP, Datastream is commonly used to capture row-level changes directly from database logs.
Streaming & Processing Layer
Captured changes are streamed through Pub/Sub and processed using Dataflow to clean, transform, and prepare data for analytics.
Analytics Destination
BigQuery is typically the final destination, offering scalable storage and high-performance querying for analytical workloads.
Capturing Changes Using Datastream
Datastream is Google Cloud’s managed CDC and replication service. It reads transaction logs directly from supported databases and continuously streams changes into Google Cloud. As a result, organizations can avoid building custom CDC mechanisms.
Key advantages of Datastream include:
- Native integration with GCP services
- Low-latency change capture
- Minimal impact on source databases
- Support for common enterprise databases
Datastream is widely adopted in environments aligned with GCP Cloud Data Engineer Training, where reliability and maintainability are critical learning outcomes.
Streaming CDC Events with Pub/Sub
Once changes are captured, Pub/Sub acts as the central messaging layer. Each database change is published as an event, enabling multiple downstream consumers to process the same data independently.
Pub/Sub is ideal for CDC pipelines because it:
- Handles sudden spikes in data volume
- Guarantees message durability
- Supports asynchronous processing
- Enables loose coupling between services
Furthermore, Pub/Sub ensures durability and message retention. For instance, if downstream processing slows down, messages remain available. Therefore, temporary failures do not cause data loss. Additionally, Pub/Sub supports high throughput. Consequently, it handles sudden spikes in transactional data effectively.
Transforming and Enriching Data Using Dataflow
Raw CDC events are not analytics-ready. Dataflow is used to process and enrich streaming data before loading it into BigQuery.
Common transformations include:
- Deduplication of events
- Handling out-of-order records
- Applying business logic
- Standardizing schemas
Furthermore, Dataflow handles complex challenges such as late-arriving events and out-of-order messages. Meanwhile, its autoscaling capabilities adapt to workload changes automatically. Consequently, pipelines remain efficient even during traffic spikes. By using Apache Beam, engineers also ensure consistency between streaming and batch logic.
Loading CDC Data into BigQuery Correctly
CDC pipelines require special handling when loading data into BigQuery. Since updates and deletes are involved, simply appending rows is not sufficient.
Best practices include:
- Writing CDC events to staging tables
- Using MERGE statements to apply changes
- Partitioning tables for performance
- Designing idempotent writes
Therefore, CDC events are often written to staging tables first. Subsequently, MERGE operations apply changes to final tables. Additionally, partitioning and clustering strategies are used to optimize performance. As a result, analytical queries remain fast even as data volume grows.
Managing Schema Evolution in CDC Pipelines
Schema changes are inevitable in real-world systems. Columns are added, data types evolve, and business requirements shift over time. Without proper handling, schema changes can silently break CDC pipelines.
On GCP, schema evolution is managed through:
- Flexible BigQuery schemas
- Version-controlled transformations
- Dataflow pipeline updates
- Schema validation checks
Proactive schema management is essential for long-term pipeline stability.
Monitoring, Reliability, and Cost Control
CDC pipelines must run continuously, making monitoring and reliability non-negotiable. Engineers track:
- Replication lag
- Pipeline failures
- Data completeness
- Resource usage
Additionally, logging and alerting enable quick responses to failures. Meanwhile, cost monitoring helps identify inefficient queries or excessive streaming usage. As a result, organizations maintain both reliability and financial control over their data platforms.
Security and Compliance Considerations
CDC pipelines often move sensitive business data. Security must be embedded into the architecture from day one.
Key security practices include:
- Encrypting data in transit and at rest
- Applying least-privilege IAM roles
- Masking sensitive fields
- Auditing data access
Additionally, audit logs help track data usage. In regulated environments, data masking is also applied. These practices are central to real-world enterprise systems and are emphasized heavily in GCP Data Engineer Training in Chennai programs.
FAQs
Conclusion
Change Data Capture pipelines are a foundational component of modern data engineering on Google Cloud. When built with the right tools and design principles, they enable real-time insights, reliable analytics, and scalable data platforms. Mastering CDC architecture prepares data engineers to meet the growing demand for always-available, trustworthy data in cloud-native environments.
TRENDING COURSES: Oracle Integration Cloud, AWS Data Engineering, SAP Datasphere
Visualpath is the Leading and Best Software Online Training Institute in Hyderabad.
For More Information about Best GCP Data Engineering
Contact Call/WhatsApp: +91-7032290546
Visit: https://www.visualpath.in/gcp-data-engineer-online-training.html


