How Do You Design an ELT Architecture on AWS?

- Introduction
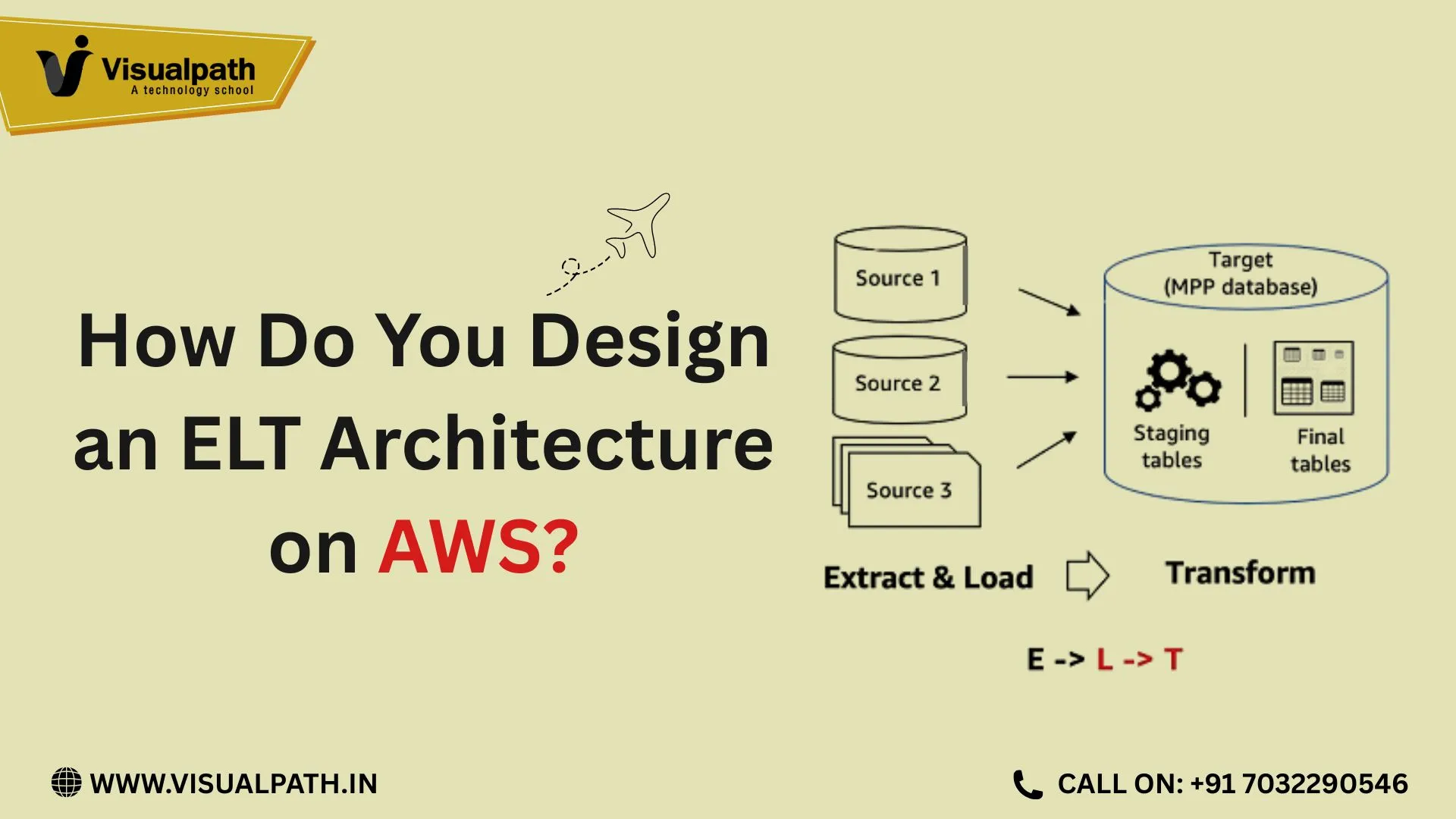
- Understanding the ELT Philosophy on AWS
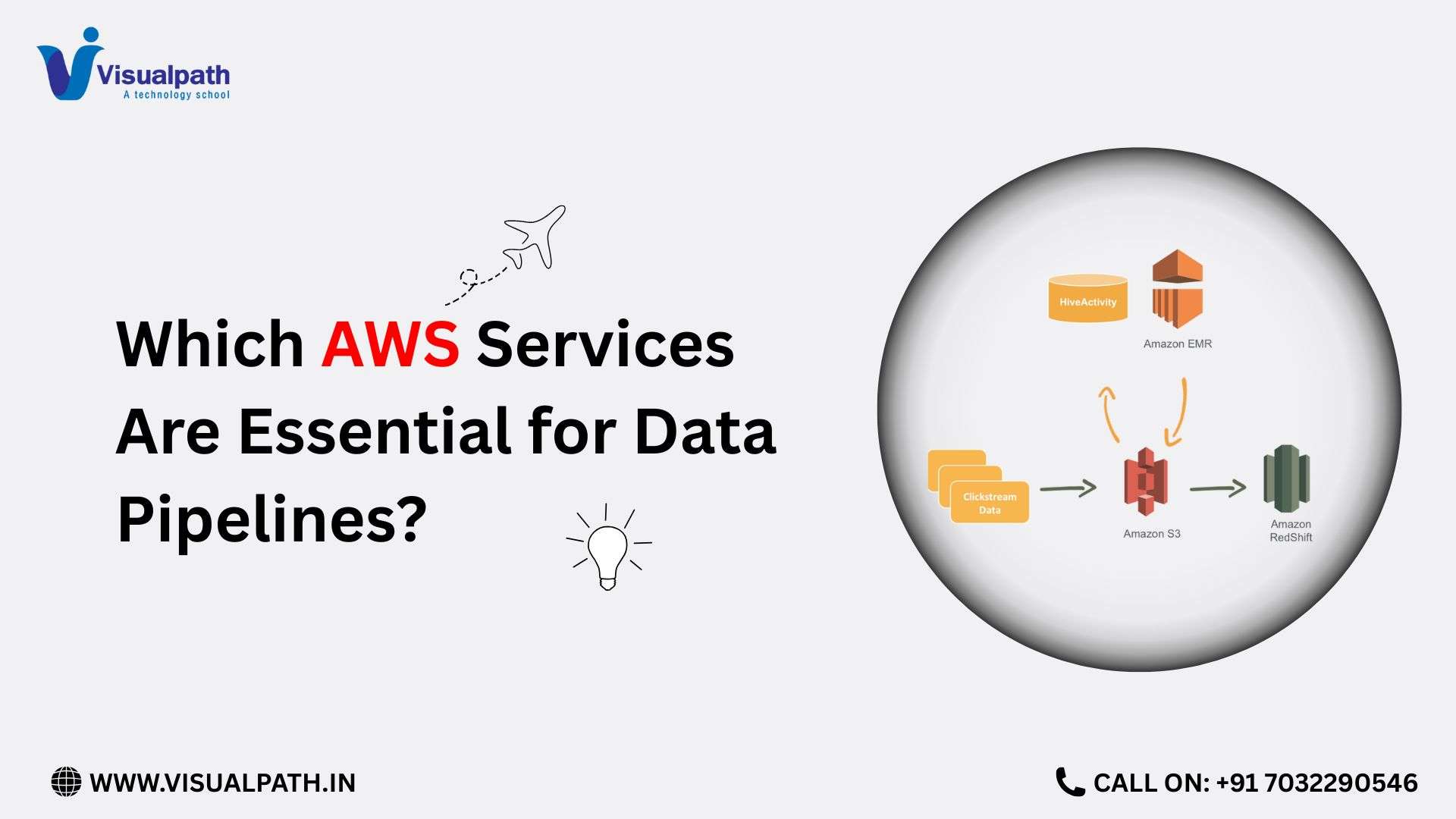
- Data Ingestion: Bringing Data into AWS
- Central Storage Layer with Amazon S3
- Transformations Inside the Analytics Layer
- Orchestration and Workflow Management
- Data Quality, Governance, and Security
- Performance and Cost Optimization
- Frequently Asked Questions (FAQs)
- Conclusion
Introduction
AWS Data Engineering has become the backbone of modern analytics as organizations move away from traditional ETL models toward faster, more flexible ELT approaches. In an ELT architecture, data is first extracted and loaded in its raw form, and transformations are performed later inside scalable analytics systems. This approach reduces ingestion complexity and allows teams to adapt quickly to changing business requirements. Many professionals learning through an AWS Data Engineering Course quickly realize that ELT is not just a design pattern, but a mindset shift that prioritizes speed, scalability, and analytical freedom.
Designing an ELT architecture on AWS requires a clear understanding of data sources, ingestion patterns, storage layers, transformation engines, and governance. When done correctly, it enables organizations to handle massive data volumes while keeping costs predictable and performance reliable.
Understanding the ELT Philosophy on AWS
ELT differs from ETL in one critical way: transformations happen after data lands in the analytics layer. On AWS, this aligns perfectly with cloud-native services that separate storage from compute. Raw data can be ingested continuously without worrying about immediate transformations, allowing teams to preserve original data for future use cases.
This approach is especially useful when dealing with evolving schemas, new business logic, or multiple analytics consumers. Instead of rebuilding pipelines, transformations can be adjusted inside query engines or data warehouses.
Data Ingestion: Bringing Data into AWS
The first step in an ELT architecture is extraction and loading. AWS offers multiple ingestion options depending on data velocity and source type.
For batch data, services like AWS Database Migration Service and scheduled ingestion jobs are commonly used to pull data from relational databases, SaaS platforms, or on-prem systems. For streaming data, Amazon Kinesis and managed Kafka services handle real-time events such as logs, IoT data, and user interactions.
The key principle at this stage is simplicity. Data is loaded as-is, without heavy processing, so ingestion pipelines remain stable even as downstream requirements change.
Central Storage Layer with Amazon S3
Amazon S3 plays a central role in ELT architectures by acting as the system of record. All incoming data—structured, semi-structured, or unstructured—is stored in S3 in its raw format. Organizing data into logical zones such as raw, refined, and curated helps maintain clarity and access control.
Partitioning data by date, region, or source significantly improves query performance later. File formats such as Parquet or ORC are often adopted over time, but the raw layer should always retain the original data for traceability and reprocessing.
This design supports teams enrolled in AWS Data Engineering online training, as it demonstrates real-world data lake practices used by large enterprises.
Transformations Inside the Analytics Layer
The defining feature of ELT is where transformations occur. Instead of transforming data before loading, AWS allows transformations directly inside analytics engines.
Amazon Redshift enables SQL-based transformations at scale, making it ideal for analytical workloads. Amazon Athena allows on-demand transformations over S3 data without infrastructure management. AWS Glue can also be used selectively for transformations that require Spark-based processing.
Because compute and storage are decoupled, teams can run complex transformations only when needed, reducing costs while maintaining flexibility.
Orchestration and Workflow Management
An ELT architecture must coordinate ingestion, transformations, and validations. AWS Step Functions and managed Apache Airflow are commonly used to orchestrate workflows.
These tools handle dependencies, retries, and failure notifications. For example, transformations should only begin after successful data ingestion. If a step fails, workflows can alert teams without affecting upstream data.
This orchestration layer is critical for maintaining reliability in production-grade systems.
Data Quality, Governance, and Security
As data volumes grow, teams must enforce governance and security from the beginning. AWS offers fine-grained access control through IAM and Lake Formation, allowing teams to manage permissions at scale.
Engineers encrypt data at rest and in transit to protect sensitive information. They also integrate data quality checks into transformation steps to maintain trust in analytical outputs. Metadata catalogs help teams understand data lineage and improve collaboration.
Many organizations rely on guidance from an AWS Data Engineering Training Institute to standardize governance and security practices.
Performance and Cost Optimization
ELT architectures deliver flexibility, but teams must actively manage performance and cost. Engineers optimize queries by partitioning data, selecting the right execution engine, and tuning workloads based on usage patterns.
Teams monitor pipelines using CloudWatch, scale compute resources only when needed, and schedule heavy transformations during low-usage periods. These practices help organizations maintain predictable costs while delivering fast analytics.
Performance optimization remains an ongoing responsibility rather than a one-time task.
Frequently Asked Questions (FAQs)
Conclusion
In real-world environments, an effective ELT design also encourages collaboration between engineering, analytics, and business teams. Since raw data is preserved, teams can revisit historical datasets, apply new logic, and answer questions that were not even considered during initial ingestion. This flexibility becomes especially valuable as organizations grow and reporting needs change.
Ultimately, a well-designed ELT architecture supports faster decision-making, reduces operational friction, and future-proofs analytics platforms. When built with clarity and discipline, it allows data teams to focus less on pipeline maintenance and more on delivering insights that actually matter to the business.
TRENDING COURSES: Oracle Integration Cloud, GCP Data Engineering, SAP Datasphere.
Visualpath is the Leading and Best Software Online Training Institute in Hyderabad.
For More Information about Best AWS Data Engineering
Contact Call/WhatsApp: +91-7032290546
Visit: https://www.visualpath.in/online-aws-data-engineering-course.html