
Top AWS Tools for Advanced Data Analytics in 2025

Introduction to Data Analytics in AWS Data Analytics plays a pivotal role in the modern business world, helping organizations derive
Introduction to Data Analytics in AWS Data Analytics plays a pivotal role in the modern business world, helping organizations derive
Introduction to AWS Data Engineering AWS Data Engineering is a cornerstone for businesses leveraging cloud technologies to manage and analyze

AWS and Azure for data science, both platforms offer robust services and tools for data professionals. However, each has its

Data Engineering in today’s cloud-driven world demands familiarity with the most effective tools and services. Amazon Web Services (AWS), as

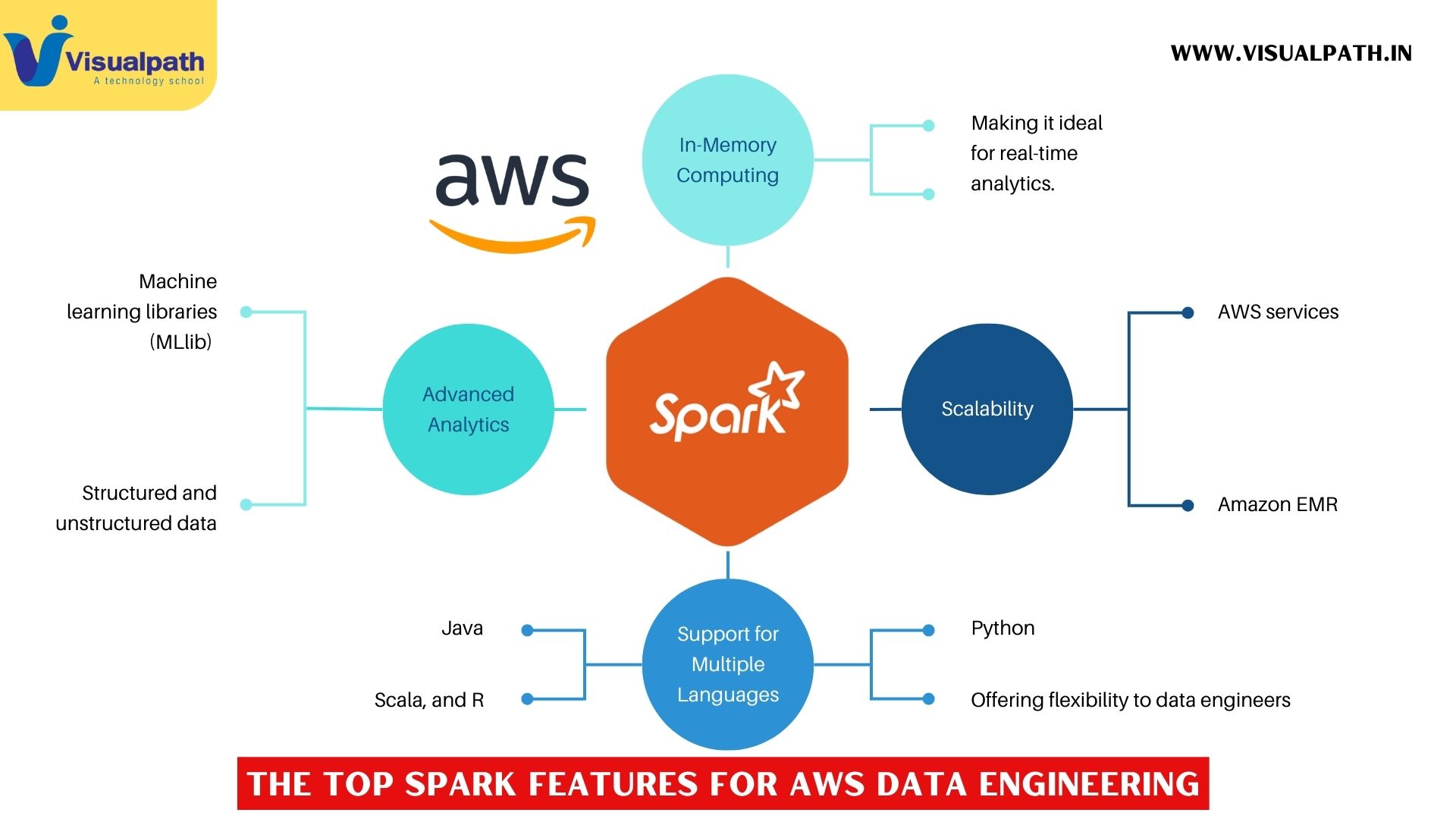
Apache Spark is a fast, open-source engine for large-scale data processing, known for its high-performance capabilities in handling big data

ETL (Extract, Transform, Load) is a critical process in data engineering, enabling the consolidation, transformation, and loading of data from